پس از اتمام این فصل ، میتوانید به سوالات زیر پاسخ دهید :
- چرا در طراحی های امروزی دسترسی بالا نیازمند است ، و چه مکانیزمی می تواند در تأمین این دسترسی بالا کمک کند؟
- چه فناوری های مختلفی عملکرد شبکه را بهینه می کنند؟
- چه مکانیسم های QoS می توانند به بهینه سازی عملکرد شبکه کمک کنند؟
- با استفاده از آنچه در این فصل و فصل های قبلی آموخته اید ، چگونه یک شبکه SOHO را بر پایه ی نیازمندی ها طراحی می کنید؟
اگر فیلم Field of Dreams را دیده باشید ، این جمله را شنیده اید: “If you build it, they will come” این جمله در شبکه های امروز صحت دارد. این شبکه ها که زمانی به دامنه داده منتقل می شدند ، اکنون می توانند داده صوتی و تصویری را حمل کنند. این نوع رسانه ها به یک شبکه نیاز دارند تا برای کاربران خود فعال و در دسترس باشد. به عنوان مثال ، سرویس تلفن شما در مقایسه با تعداد دفعاتی که شبکه داده شما در دسترس نیست ، چند بار غیرقابل دسترسی است. متأسفانه ، شبکه های داده به طور سنتی کمتر از شبکه های صوتی قابل اعتماد هستند. با این حال ، شبکه های داده امروز اغلب شبکه های صوتی هستند ، که به افزایش تقاضا برای uptime کمک می کند. سرویس های صوتی یکپارچه مانند درگاه های تماس و کنترل تماس می توانند در یک یا چند دستگاه شبکه ادغام شوند و از پهنای باند موجود در LAN و WAN استفاده کنند. فراتر از در دسترس بودن ، شبکه های امروزبه ابزارهای بهینه سازی نیاز دارند . این کتاب قبلاً به چندین ابزار بهینه سازی شبکه پرداخته است که در این فصل بررسی می شود. [۱](QoS) دسته کاملی از ابزارهای بهینه سازی شبکه است. QoS ، مثلا ، می تواند به اولویت درمان ترافیک latency-sensitive (حساس به تأخیر) ، مانند Voice over IP (VoIP) بپردازد. این فصل بخشی را به کاوش این ابزار اختصاص داده است. سرانجام ، بر اساس آنچه در این فصل می آموزید و آنچه در فصول قبلی آموخته اید ، با یک چالش طراحی روبرو می شوید.
[۱] Quality of service
مباحث بنیاد
High Availability
اگر سوئیچ یا روتر شبکه کار خود را متوقف کند (به این معنی است که خطای شبکه رخ می دهد) ، ارتباط از طریق شبکه ممکن است مختل شود و در نتیجه یک شبکه در دسترس کاربران قرار نگیرد. بنابراین ، در دسترس بودن شبکه که uptime نامیده می شود ، یکی از موارد مهم در طراحی است. به عنوان مثال ، این ملاحظه ممکن است شما را به اضافه کردن دستگاه های مقاوم در برابر خطا و لینک های مقاوم در برابر خطا بین این دستگاه ها سوق دهد. این بخش اندازه گیری دسترسی پذیری بالا و همچنین مجموعه ای از ملاحظات طراحی دسترسی پذیری بالا را مورد بحث قرار می دهد.
High-Availability Measurement
در دسترس بودن یک شبکه با زمان به کارگیری آن در طول یک سال اندازه گیری می شود. به عنوان یک طراح ، یکی از اهداف شما انتخاب مولفه ها ، توپولوژی ها و ویژگی هایی است که دسترسی به شبکه را در پارامترهای خاص (به عنوان مثال budget) به حداکثر می رساند. دسترس پذیری را با قابلیت اطمینان اشتباه نگیرید. به عنوان مثال ، یک شبکه reliable بسته های زیادی را رها نمی کند ، در حالی که یک شبکه available فعال و عملکردی است.
توجه
دسترس پذیری شبکه با کاهش[۲](MTTR) و افزایش[۳](MTBF) افزایش می یابد. بنابراین ، انتخاب دستگاه های شبکه قابل اعتماد که سریع تعمیر شوند برای طراحی با قابلیت دسترسی بالا بسیار مهم است. هدف دیگر در طراحی شما ممکن است تأمین الزامات مندرج در [۴](SLA) باشد. SLA تعهدی رسمی است که بین ارائه دهنده خدمات و مشتری وجود دارد. جنبه های خدمات IT ارائه شده – کیفیت ، در دسترس بودن ، مسئولیت های خاص – بین ارائه دهنده خدمات و کاربر خدمات توافق شده است. امروزه SLA های سختگیرانه در شبکه بیشتر و بیشتر دیده می شوند زیرا هرچه بیشتر سرویس های ابری به فضای IT دسترسی پیدا می کنند. ارائه دهنده cloud یک ارائه دهنده خدمات تخصصی است و مصرف کننده cloud کلاینت است.
طراحی شبکه تحمل خطا(Fault-Tolerant)
[۲] mean time to repair
[۳] mean time between failures
[۴] service-level agreement
دو روش برای طراحی یک شبکه تحمل خطا به شرح زیر است:
- Single points of failure : اگر خرابی یک دستگاه شبکه یا لینک (به عنوان مثال ، سوئیچ ، روتر یا اتصال WAN) منجر به غیرقابل دسترس بودن شبکه شود این دستگاه یا لینک یک نقطه خرابی است. برای از بین بردن نقاط خرابی از طراحی خود ، ممکن است لینک های اضافی و سخت افزار اضافی را در آن قرار دهید. به عنوان مثال ، برخی از سوئیچ های سطح بالا اترنت از دو منبع تغذیه پشتیبانی می کنند و در صورت خرابی یک منبع تغذیه ، سوئیچ با استفاده از منبع تغذیه پشتیبان به کار خود ادامه می دهد. افزونگی لینک ، همانطور که در شکل ۹-۱ نشان داده شده است ، با استفاده از بیش از یک لینک فیزیکی قابل دستیابی است. اگر یک اتصال واحد بین سوئیچ و روتر از بین برود ، شبکه به دلیل افزونگی لینک موجود ، از بین نمی رود.
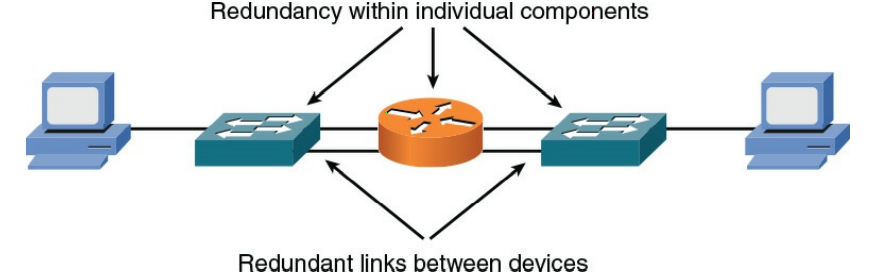
شکل ۱-۹ : Redundant Network with Single Points of Failure
- No single points of failure : این شبکه ها شامل اجزای اضافی زیر ساخت شبکه مانند سوییچ ها و روتر ها است ، علاوه بر ان این دستگاه ها با لینک های اضافی به هم متصل میشوند اگر چه میزبان شبکه میتواند دارای دو کارت رابط شبکه (NICs) باشد که هر کدام به یک سوییچ متفاوت وصل میشوند بخاطر افزایش هزینه ها چنین طراحی هایی به ندرت دیده میشود همانطور که در شکل ۹-۲ دیده میشود شبکه no single points of failure اجازه می دهد تا هر سوئیچ یا روتریا هر لینک دیگری در backbone خراب شود ، در حالی که اتصال شبکه به انتهای شبکه حفظ می شود.
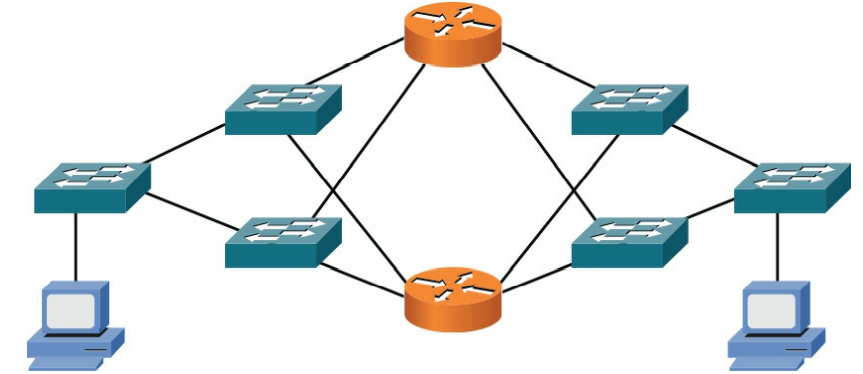
شکل ۲-۹ : Redundant Network with No Single Point of Failure
از این دو روش برای طراحی شبکه تحمل خطا می توان با هم استفاده کرد تا دسترس پذیر بودن شبکه را افزایش داد .
افزونگی سخت افزار
وجود پردازنده های افزونگی مسیر در یک سوئیچ یا شاسی روتر قابلیت اطمینان (reliability )شاسی را افزایش می دهد. اگر یک سوئیچ چند لایه دارای دو پردازنده مسیر باشد ، مثلا ، یکی از پردازنده های مسیر می تواند فعال باشد ، در صورت عدم دسترسی به پردازنده فعال ، پردازنده مسیر دیگر در حالت standing است. یک سیستم نهایی می تواندافزونگی NIC داشته باشد. دو حالت افزونگی NIC به صورت زیر است :
- Active-active: هر دو NIC همزمان فعال هستند و هرکدام آدرس MAC خاص خود را دارند. این مسئله عیب یابی را پیچیده تر می کند ، در حالی که عملکرد کمی بهتر از روش آماده به کار فعال به شما ارائه می دهد.
- Active-standby: همزمان فقط یک NIC فعال است. این رویکرد به کلاینت امکان می دهد حتی در صورت خرابی NIC ، دارای یک آدرس MAC و آدرس IP واحد باشد.
افزونگی NIC به دلیل هزینه و سربار اجرایی بالا اغلب در میزبان شبکه به جای رایانه کلاینت کاربر نهایی دیده می شود .
توجه
فروشندگان مختلف اصطلاحات مختلفی را برای اشاره به ترکیب NIC ها برای افزونگی سخت افزار به کار می برند. دو رایج ترین این اصطلاحات ، NIC teaming و NIC bonding است. CompTIA ، NIC teaming را ترجیح می دهد.
یکی دیگر از روش های قدرتمند افزونگی سخت افزار به صورت خوشه بندی رایانه ای(computer clustering) است . یک خوشه رایانه ای شامل مجموعه ای از رایانه های کاملاً متصل است که با هم کار می کنند. از بسیاری جهات ، کلاینت ها به آنها به عنوان یک سیستم واحد نگاه می کنند. سرورهای موجود در یک خوشه معمولاً از طریق شبکه های محلی سریع به یکدیگر متصل می شوند و هر گره نمونه خود را از یک سیستم عامل اجرا می کند. در بیشتر شرایط ، همه گره ها از سخت افزار یکسان و سیستم عامل یکسانی استفاده می کنند ، اگرچه در برخی از تنظیمات ، می توان از سیستم عامل های مختلفی بر روی هر رایانه ، یا حتی سخت افزارهای مختلف استفاده کرد. خوشه های رایانه ای در نتیجه همگرایی روندهای محاسبات ، از جمله در دسترس بودن ریز پردازنده های کم هزینه ، شبکه های پرسرعت و نرم افزار برای محاسبات توزیع شده با کارایی بالا ظاهر می شوند . آنها از طیف گسترده ای از کاربرد و استقرار ، از خوشه های تجاری کوچک با تعداد انگشت شماری گره گرفته تا سریعترین ابر رایانه های جهان استفاده می کنند.
افزونگی لایه ۳ :
سیستم های پایانی که پروتکل مسیریابی را اجرا نمی کنند ، به یک gateway پیش فرض اشاره می کنند. gateway پیش فرض به طور سنتی آدرس IP یک روتر در local subnet است. با این حال ، اگر روتر gateway پیش فرض خراب شود ، سیستم های پایانی قادر به ترک زیر شبکه خود نیستند. در فصل ۴ ، “فناوری اترنت” ، چهار فناوری اضافه کاری در first-hopمعرفی شده است (که افزونگی لایه ۳ را ارائه می دهد)
- [۱](HSRP): رویکرد اختصاصی سیسکو برای افزونگی first-hop. شکل ۹-۳ یک نمونه توپولوژی HSRP را نشان می دهد
[۱] Hot Standby Router Protocol
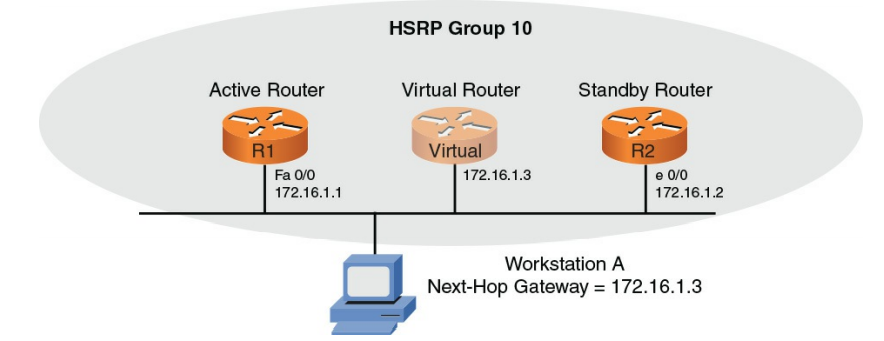
شکل ۳-۹ : نمونه ای از توپولوژی HSRP
در شکل ۹-۳ ، ایستگاه کاری A با یک درگاه پیش فرض از ۱۷۲٫۱۶٫۱٫۳ پیکربندی شده است. برای جلوگیری از تبدیل شدن دروازه پیش فرض به یک نقطه خرابی ، HSRP روترهای R1 و R2 را قادر می سازد تا به عنوان دروازه پیش فرض عمل کرده و از آدرس IP مجازی گروه HSRP پشتیبانی کنند (۱۷۲٫۱۶٫۱٫۳) ، اگرچه فقط یکی از روترها به عنوان gateway پیشفرض در هر زمان عمل می کند . در شرایط عادی ، روتر R1 (یعنی روتر فعال) بسته های ارسال شده به IP مجازی ۱۷۲٫۱۶٫۱٫۳ را ارسال می کند. با این حال ، اگر روتر R1 در دسترس نباشد ، روتر R2 (یعنی روتر آماده به کار) می تواند امور را کنترل کرده و ترافیک ارسال شده به ۱۷۲٫۱۶٫۱٫۳ را شروع کند. توجه داشته باشید که نه روتر R1 و نه R2 دارای رابط فیزیکی با ادرس IP 172.16.1.3 نیستند. در عوض ، یک روتر منطقی (روتر مجازی نامیده می شود) که توسط روترهای R1 یا R2 سرویس می شود ، آدرس IP 172.16.1.3 را حفظ می کند.
- (CARP): CARP[1] یک نوع استاندارد باز از HSRP است.
- (VRRP): VRRP[2] یک استاندارد باز IETF است که به روشی مشابه HSRP اختصاصی سیسکو کار می کند.
- (GLBP): GLBP[3] یکی دیگر از پروتکل های first-hop redundancy است که اختصاصی سیستم های سیسکو است.
با استفاده از هر یک از این فناوری ها ، آدرس MAC و آدرس IP یک درگاه پیش فرض توسط بیش از یک روتر (یا سوئیچ چند لایه) قابل سرویس دهی هستند. بنابراین ، اگر یک درگاه پیش فرض از دسترس خارج شود ، روتر دیگر (یا سوئیچ چند لایه) می تواند سیستم را مدیریت کند و همچنان آدرس های MAC و IP مشابه را سرویس می کند. نوع دیگری از افزونگی لایه ۳ با داشتن چندین پیوند بین دستگاه ها و انتخاب یک پروتکل مسیریابی که بین پیوندها توازن ایجاد می شود ، حاصل می شود. پروتکل کنترل تجمع پیوند (LACP) ، که در فصل ۴ مورد بحث قرار گرفت ، به شما امکان می دهد چندین پیوند فیزیکی به یک رابط منطقی اختصاص دهید ، که به عنوان یک پیوند واحد به پردازنده مسیر ظاهر می شود. شکل ۹-۴ توپولوژی شبکه را با استفاده از LACP نشان می دهد.
[۱] Common Address Redundancy Protocol
[۲] Virtual Router Redundancy Protocol
[۳] Gateway Load Balancing Protocol

شکل ۴-۹ : نمونه ای از توپولوژی LACP
ملاحظات طراحی شده برای شبکه های با دسترسی بالا
هنگام طراحی شبکه برای دسترسی بالا ، باید به سوالات زیر پاسخ داد :
- افزونگی ماژول و شاسی در کجا استفاده خواهد شد؟ افزونگی ماژول با اجازه دادن به یک ماژول در صورت خراب شدن ماژول اولیه ، افزونگی را درون یک شاسی فراهم می کند. افزونگی شاسی با داشتن بیش از یک شاسی ، افزونگی را فراهم می کند ، بنابراین ، حتی در صورت خرابی شاسی یا پیوند مسیری را از مبدا به مقصد فراهم می کند.
- چه ویژگی های افزونه نرم افزاری مناسب است؟
- چه ویژگی های از پروتکل بر الزامات طراحی تأثیر می گذارد؟
- از چه ویژگی های افزونگی باید برای تأمین برق دستگاه زیرساخت استفاده شود – به عنوان مثال ، با استفاده از منبع تغذیه بدون وقفه (UPS) ، ژنراتور یا منبع تغذیه دوگانه؟
- برای حفظ شرایط محیطی (به عنوان مثال واحدهای تهویه مطبوع دوگانه) باید از چه ویژگی های افزونگی استفاده کرد؟
- آیا در صورت قطع اتصال با یکی از مدارها ، مدارهای دوگانه ارائه می شود؟
- چه استراتژی پشتیبان گیری برای زیرساخت و داده های کاربر وجود دارد؟ استراتژی های مختلف پشتیبان گیری شامل موارد زیر است:
- Full: پشتیبان گیری از همه مجموعه داده ها. اگرچه این ایمن ترین و جامع ترین روش برای اطمینان از در دسترس بودن داده ها است ، اما می تواند زمانبر و هزینه بر باشد.
- Incremental: این فقط از داده هایی که از نسخه پشتیبان قبلی تغییر کرده اند پشتیبان تهیه می کند.
- Differential: این از آنجا که با پشتیبان گیری کامل شروع می شود ، مشابه پشتیبان افزایشی است و سپس پشتیبان گیری های بعدی فقط حاوی داده هایی هستند که تغییر کرده اند. تفاوت این است که در حالی که یک نسخه پشتیبان افزایشی فقط شامل داده هایی است که از نسخه پشتیبان قبلی تغییر کرده اند ، یک نسخه پشتیبان دیفرانسیل شامل تمام داده هایی است که از آخرین نسخه پشتیبان کامل تغییر کرده اند.
- Snapshots: این یک کپی فقط خواندنی از مجموعه داده است که در یک زمان مشخص بسته می شود. این نوع فناوری برای تهیه پشتیبان اغلب با ماشین های مجازی و اشیا سیستم فایل استفاده می شود.
بهترین روشهای در دسترس بودن بالا
پنج روش مناسب برای طراحی شبکه های با قابلیت دسترسی بالا به صورت زیر است :
- مشخص کردن بودجه برای تامین اعتبار و ویژگی هایی با دسترس پذیری بالا
- دسته بندی کردن برنامه های تجاری به نمایه هایی که هریک از آنها به سطح مشخصی از دسترسی نیاز دارند .
- تعیین استاندارد های عملکردی برای سولوشن هایی با دسترسی بالا
- مشخص کردن نحوه ی مدیریت و اندازه گیری سولوشن هایی با دسترسی بالا
اگرچه می توان شبکه های موجود را به شبکه های بسیار در دسترس تبدیل کرد ، اما طراحان شبکه می توانند با ادغام بهترین روش ها و فن آوری های با دسترسی بالا در طراحی اولیه یک شبکه ، چنین هزینه هایی را کاهش دهند.
ذخیره مطالب
در فصل ۳ ، “اجزای شبکه” ، مفهوم موتور محتوا (همچنین به عنوان caching engine نیز شناخته می شود) معرفی شد. موتور محتوا یک ابزار شبکه است که می تواند یک کپی از محتوای ذخیره شده در جای دیگر (به عنوان مثال ، یک نمایش ویدیویی واقع در یک سرور در دفتر مرکزی شرکت) دریافت کند و آن محتوا را به مشتریان محلی ارائه دهد ، بنابراین از پهنای باند IP WAN می کاهد. شکل ۹-۵ نمونه توپولوژی را با استفاده از موتور محتوا به عنوان فناوری بهینه سازی شبکه نشان می دهد.
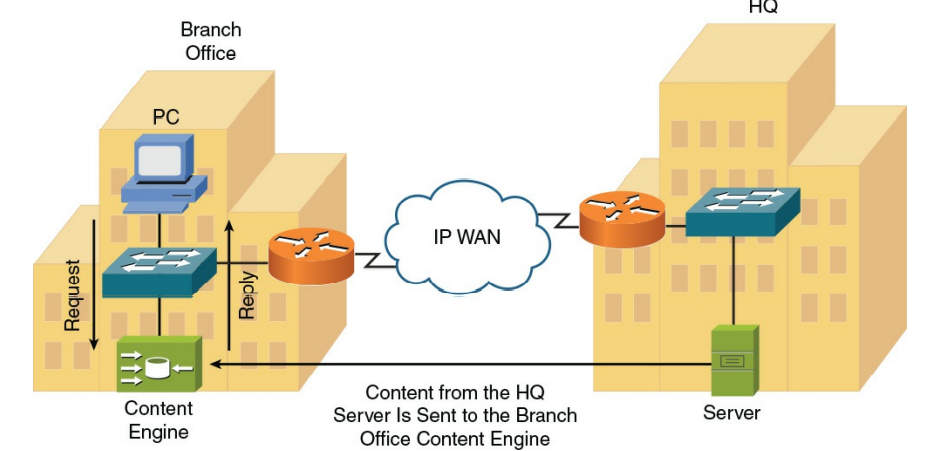
شکل ۵-۹ : نمونه از توپولوژی Content Engine
Load Balancing
یکی دیگر از فناوری های بهینه سازی شبکه که در فصل ۳ معرفی شد ، content switching بود که به شما اجازه می دهد درخواستی که به یک فریم سرور وارد می شود در چندین سرور حاوی محتوای یکسان توزیع شود. این روش برای تعادل بار ، بار سرورهای منفرد در یک فریم سرور را کاهش می دهد و اجازه می دهد تا سرورها بدون ایجاد اختلال در دسترسی به داده های فریم سرور ، برای نگهداری از فریم خارج شوند. شکل ۹-۶ یک نمونه توپولوژی تغییر محتوا را نشان می دهد که تعادل بار را در پنج سرور (حاوی محتوای یکسان) در فریم سرور انجام می دهد
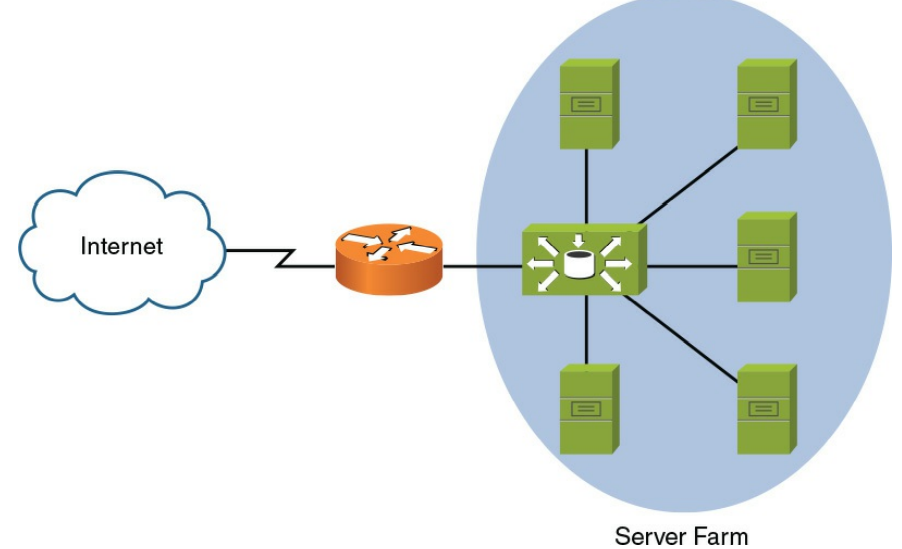
شکل ۶-۹ :نمونه ای از توپولوژی Content-Switching
افزونگی سخت افزار
همچنین می توان تعداد اضافی سایت را در زیرساخت شبکه خود طراحی کرد. این کار به داده ها و تجهیزات اضافی واقع در مناطق جغرافیایی دور نیاز دارد. در صورت بروز مشکل در سایت اصلی شما ، با چه سرعتی می توان از زیرساخت فناوری اطلاعات شما پشتیبان تهیه و اجرا کرد؟ معمولاً به صورت زیر اندازه گیری می شود:
- Cold site: بازیابی امکان پذیر است اما دشوار و زمانبر است.
- Warm site: بازیابی نسبتاً سریع امکان پذیر است ، اما ممکن است با تمام منابع و پاسخگویی سایت اصلی برابر نباشد.
- Hot site: زمان خرابی با سطح خدمات تقریباً یکسان کم است.
فناوری های QoS
کیفیت خدمات (QoS) مجموعه فناوری هایی است که به شما امکان می دهد عملکرد شبکه را برای انواع ترافیک انتخابی بهینه کنید. به عنوان مثال ، در شبکه های همگرا امروزی (یعنی شبکه هایی که همزمان انتقال صدا ، ویدئو و داده ها را انجام می دهند) ، برخی از برنامه ها (به عنوان مثال صوتی) ممکن است نسبت به برنامه های دیگر (مثلاً یک پرونده FTP) تأخیر (یا Latency) تحمل کنند. حساسیت تأخیردر FTP file نسبت به تماس VoIP call کمتر است). خوشبختانه با استفاده از فناوری های QoS می توانید تشخیص دهید کدام نوع ترافیک ابتدا باید ارسال شوند ، چه مقدار پهنای باند برای انواع ترافیک اختصاص داده شود ، در صورت ازدحام ابتدا کدام یک از ترافیک ها کاهش یابد و چگونه بیشترین بهره را ببرید. در این بخش QoS و مجموعه ای از سازوکارهای QoS معرفی می شود.
مقدمه ای بر QoS
کمبود پهنای باند مسئله تحت الشعاع ترین مشکلات کیفیت است. به طور خاص ، در صورت کمبود پهنای باند ، بسته ها ممکن است یک یا چند مورد از علائم نشان داده شده در جدول ۹-۱ را دارا باشند .
جدول ۱-۹ : سه دسته از Quality Issues

خوشبختانه ، ویژگی های QoS موجود در بسیاری از روترها و سوئیچ ها می توانند ترافیک مهم را تشخیص دهند و سپس آن ترافیک را به روشی خاص درمان کنند. به عنوان مثال ، ممکن است بخواهید پهنای باند ۱۲۸ کیلوبایت بر ثانیه را برای ترافیک VoIP خود اختصاص دهید و به آن اولویت درمان برای ترافیک اختصاص دهید. در نظر داشته باشید که آب از طریق یک سری لوله با قطرهای مختلف جریان دارد. میزان جریان آب از طریق آن لوله ها به میزان جریان آب از طریق لوله با کمترین قطر محدود می شود. به همین ترتیب ، هنگامی که یک بسته از مبدا خود به مقصد می رود ، پهنای باند موثر آن پهنای باند کندترین پیوند در آن مسیر است. به عنوان مثال ، شکل ۹-۷ را در نظر بگیرید. توجه داشته باشید که کمترین سرعت لینک ۲۵۶Kbps است. این ضعیف ترین پیوند به پهنای باند موثر بین سرویس گیرنده و سرور تبدیل می شود.
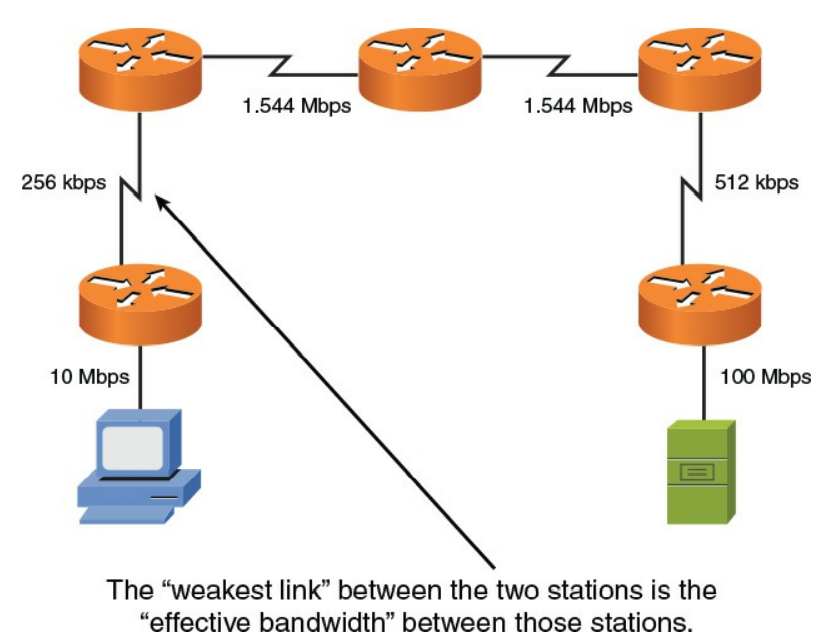
شکل ۷-۹ : تاثیر پهنای باند ۲۵۶Kbps
از آنجا که چالش اصلی QoS کمبود پهنای باند است ، سوال منطقی این است که “چگونه پهنای باند موجود را افزایش دهیم؟” پاسخ به این سوال این است که اغلب “پهنای بباند بیشتر اضافه کنیم “. اگرچه جایگزینی برای پهنای باند بیشتر وجود ندارد ، اما اغلب هزینه نسبتاً بالایی دارد. شبکه خود را با یک سیستم بزرگراه در یک شهر بزرگ مقایسه کنید. در ساعات شلوغی ، خطوط بزرگراه مملو از ترافیک هستند ، اما ممکن است در دوره های دیگر روز از خطوط کم استفاده شود. بجای اینکه فقط خطوط بیشتری ایجاد کنند تا بیشترین میزان ترافیک را داشته باشند ، مهندسان بزرگراه ممکن است یک خط carpool اضافه کنند. اتومبیل های دارای دو یا چند سوارکار می توانند از خط رزرو carpool استفاده کنند زیرا در بزرگراه دارای اولویت بیشتری هستند. به همین ترتیب ، می توانید از ویژگی های QoS استفاده کنید تا در زمان ازدحام شبکه ، با کاربردهای مهم ، درمان با اولویت بیشتری داشته باشید.
مراحل پیکربندی QoS
هدف اصلی “برای طبقه بندی ترافیک و اعمال خط مشی برای آن دسته از ترافیک ، مطابق با سیاست QoS.” درک این هدف اساسی QoS می تواند به شما کمک کند سه مرحله اساسی برای پیکربندی QoS را بهتر درک کنید:
مرحله ۱٫ تعیین الزامات عملکرد شبکه برای انواع مختلف ترافیک. به عنوان مثال ، این توصیه های طراحی را برای ترافیک صوتی ، تصویری و داده در نظر بگیرید:
- صدا: بیش از ۱۵۰ میلی ثانیه تاخیر یک طرفه ؛ بیش از ۳۰ میلی ثانیه لرزش. و بیش از ۱٪ از دست دادن بسته.
- ویدئو: بیش از ۱۵۰ میلی ثانیه تأخیر یک طرفه برای برنامه های صوتی تعاملی (به عنوان مثال ، کنفرانس ویدیویی) ؛ بیش از ۳۰ میلی ثانیه لرزش. بیش از ۱٪ از دست دادن بسته.
- داده ها: برنامه ها نیازهای تأخیر و ضرر متفاوتی دارند. بنابراین ، برنامه های داده باید در کلاس های از پیش تعریف شده ترافیک دسته بندی شوند ، جایی که هر کلاس با ویژگی های خاص تاخیر و loss تنظیم شده است.
مرحله ۲٫ ترافیک را به دسته های خاصی تقسیم کنید. به عنوان مثال ، ممکن است دسته ای به نام Low Delay داشته باشید و تصمیم بگیرید که بسته های صوتی و تصویری را در آن دسته قرار دهید. همچنین ممکن است کلاس Low Priority داشته باشید ، که ترافیکی مانند بارگیری موسیقی از اینترنت را در آن قرار می دهید.
مرحله ۳٫ خط مشی QoS خود را مستند کنید و آن را در دسترس کاربران خود قرار دهید. سپس ، به عنوان مثال ، اگر کاربری شکایت دارد که برنامه های بازی شبکه ای او دارای سرعتی کند هستند ، می توانید آنها را به خط مشی QoS شرکت خود هدایت کنید ، که شرح می دهد چگونه برنامه هایی مانند بازی های شبکه بهترین درمان را دارند در حالی که ترافیک VoIP درمان اولویت دارد. اجرای واقعی این مراحل براساس دستگاه خاصی که پیکربندی می کنید متفاوت است. در برخی موارد ، ممکن است از رابط خط فرمان (CLI) یک روتر یا سوئیچ استفاده می کنید. در موارد دیگر ، ممکن است نوعی رابط کاربری گرافیکی (GUI) داشته باشید که از طریق آن QoS را روی روترها و سوئیچ های خود پیکربندی کنید.
اجزای QoS
ویژگی های QoS در یکی از سه دسته بندی نشان داده شده در جدول ۹-۲ طبقه بندی می شوند.
جدول ۲-۹ :سه دسته از مکانیزم های QoS
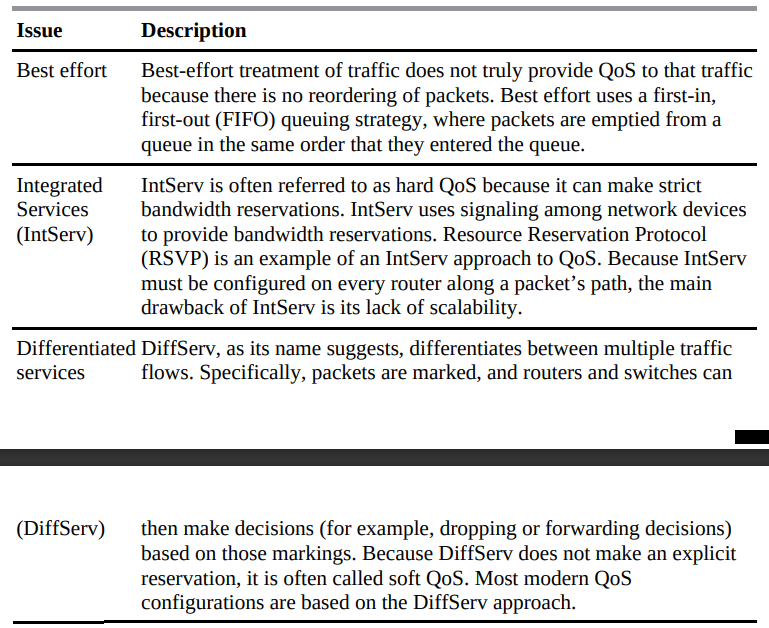
شکل ۹-۸ خلاصه این سه دسته QoS است.
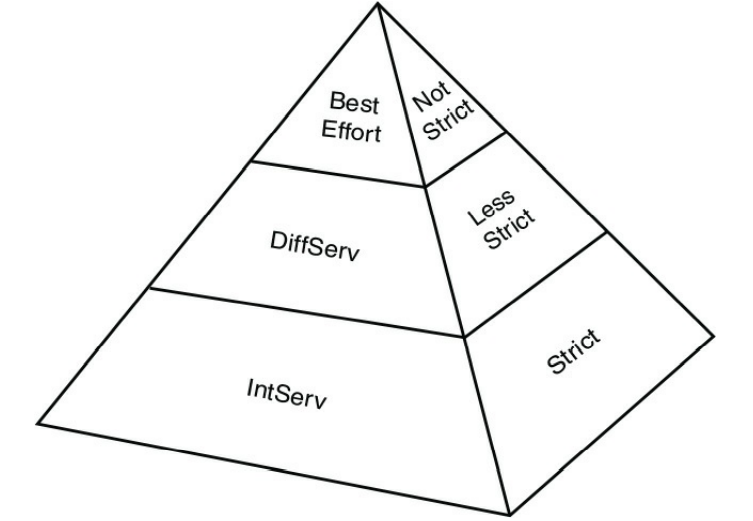
شکل ۸-۹ :کتگوری های QOS
مکانیسم های QoS
همانطور که قبلاً ذکر شد ، رویکرد DiffServ ، QoS ترافیک را علامت گذاری می کند. با این حال ، برای تأثیر علامت گذاری بر رفتار ترافیک ، یک ابزار QoS باید به آن علامت ها مراجعه کند و بسته ها را براساس آنها تغییر دهد. در زیر مجموعه ای از مکانیسم های معمول QoS آورده شده است:
- طبقه بندی (Classification)
- نشانه گذاری (Marking)
- مدیریت ازدحام(Congestion management)
- جلوگیری از احتقان(Congestion avoidance)
- سیاست گذاری و شکل دادن(Policing and shaping)
- کارایی لینک(Link efficiency)
بخشهای زیر هر مکانیزم QoS را با جزئیات شرح می دهد.
طبقه بندی
طبقه بندی فرآیند قرار دادن ترافیک در دسته های مختلف است. از چندین ویژگی می توان برای طبقه بندی استفاده کرد. به عنوان مثال ، POP3 ، IMAP ، SMTP و ترافیک Exchange می توانند در یک کلاس E-MAIL قرار بگیرند. با این حال ، طبقه بندی هیچ بیتی را در کادر یا بسته تغییر نمی دهد.
نشانه گذاری
علامت گذاری بیت ها را در یک قاب ، سلول یا بسته تغییر می دهد تا نشان دهد که چگونه شبکه باید با آن ترافیک رفتار کند. علامت گذاری به تنهایی نحوه رفتار شبکه با یک بسته را تغییر نمی دهد. با این وجود ابزارهای دیگر (مانند ابزارهای queuing ) می توانند به آن علامت ها مراجعه کنند و براساس علامت گذاری ها تصمیم بگیرند. مارک های مختلف بسته وجود دارد. به عنوان مثال ، در داخل هدر IPv4 ، یک بایت وجود دارد که نوع سرویس (ToS) نامیده می شود. همانطور که در شکل ۹-۹ نشان داده شده است ، می توانید بسته ها را با استفاده از بیت های بایت ToS ، با استفاده از IP Precedence یا نقطه کد سرویس متفاوت (DSCP) علامت گذاری کنید.
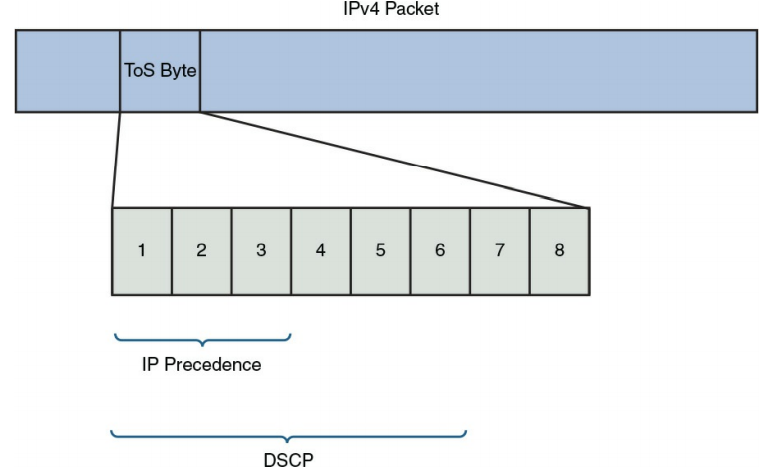
شکل ۹-۹ : ToS Byte
IP Precedence از سه بیت سمت چپ در بایت ToS استفاده می کند. با سه بیت ، علامت گذاری IP Precedence می تواند از ۰ تا ۷ باشد. که ، ۶ و ۷ نباید استفاده شود زیرا این مقادیر برای استفاده در شبکه اختصاص یافته است. همچنین می توانید DSCP را انتخاب کنید ، که از شش بیت سمت چپ در بایت ToS استفاده می کند. شش بیت ۶۴ مقدار ممکن را ارائه می دهد (۰–۶۳).
Congestion Management
وقتی دستگاهی مانند سوئیچ یا روتر سریعتر از میزان قابل انتقال ، ترافیک دریافت می کند ، دستگاه سعی می کند ترافیک اضافی را بافر (یا ذخیره) کند تا پهنای باند در دسترس قرار گیرد. به این فرآیند بافر ، queuing یا مدیریت ازدحام گفته می شود. با این حال ، یک الگوریتم queuing ، مانند [۱](WFQ) ، [۲](LLQ) یا [۳](WRR) ، می تواند در روترها و سوئیچ ها پیکربندی شود. همانطور که در شکل ۹-۱۰ نشان داده شده است ، این الگوریتم ها بافر رابط را به چندین صف منطقی تقسیم می کنند. سپس الگوریتم صف بندی بسته ها را به ترتیب و مقدار تعیین شده توسط پیکربندی الگوریتم ، از آن صف های منطقی تخلیه می کند. به عنوان مثال ، ترافیک می تواند ابتدا از یک صف اولویت دار (که ممکن است شامل بسته های VoIP باشد) تا سقف پهنای باند مشخص ارسال شود ، پس از آن بسته ها از یک صف دیگر ارسال می شوند
[۱] weighted fair queuing
[۲] low-latency queuing
[۳] weighted round-robin
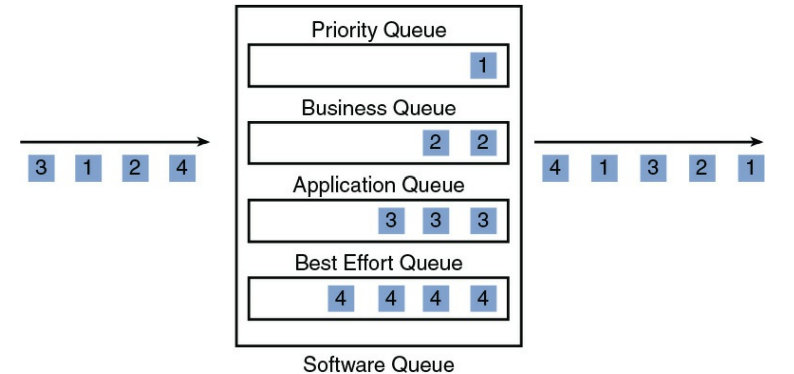
شکل ۱۰-۹ : مثال Queuing
Congestion Avoidance
اگر صف خروجی یک رابط به اندازه کافی پر شود ، بسته های تازه وارد کنار گذاشته می شوند . برای جلوگیری از این رفتار ، می توان از روش Congestion Avoidance به نام [۱](RED) استفاده کرد ، همانطور که در شکل ۹-۱۱ نشان داده شده است. پس از رسیدن عمق صف به سطح قابل تنظیم (حداقل آستانه) ، RED احتمال دور انداختن بسته را معرفی می کند. با افزایش عمق صف ، امکان دور ریختن تا رسیدن به حداکثر آستانه قابل تنظیم افزایش می یابد. بعد از اینکه عمق صف با اولویت خاصی از حداکثر آستانه ترافیک عبور کرد ، ۱۰۰٪ احتمال کنار گذاشتن آن نوع ترافیک وجود دارد. اگر آن بسته های دور ریخته شده مبتنی بر TCP (connection oriented) باشند ، فرستنده می داند کدام بسته ها کنار گذاشته می شوند و می تواند بسته ها را دوباره انتقال دهد. با این حال ، اگر آن بسته ها مبتنی بر UDP (connectionless) باشند ، فرستنده نشانه ای از افتادن بسته ها دریافت نمی کند.
[۱] random early detection
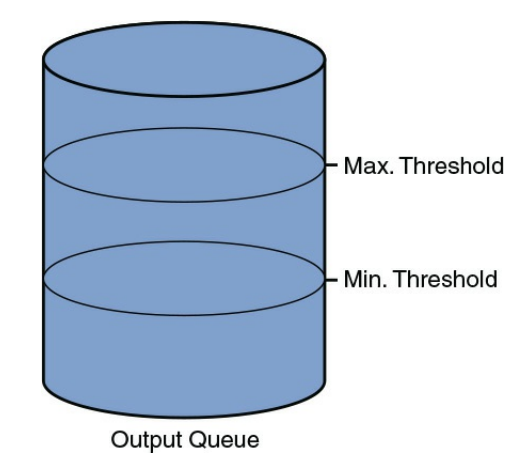
شکل ۱۱-۹ : Random Early Detection (RED)
Policing and Shaping
به جای ایجاد حداقل پهنای باند برای انواع خاص ترافیک ، ممکن است بخواهید پهنای باند موجود را محدود کنید. هر دو روش policing و ابزارهای ایجاد ترافیک می توانند این هدف را محقق کنند. در مجموع ، به این ابزارها traffic conditionersگفته می شود. از Policing می توان در جهت ورودی یا خروجی استفاده کرد ، و به طور معمول بسته هایی را که بیش از حد نرخ پیکربندی شده اند ، دور می زند ، که می توانید برای انواع خاص ترافیک محدودیت سرعت در نظر بگیرید. چون Policing بسته ها را رها می کند ، در نتیجه انتقال مجدد انجام می شود و برای رابط های با سرعت بالاتر توصیه می شود. شکل دادن به بافرها (و بنابراین تأخیر) باعث افزایش ترافیک بیش از نرخ پیکربندی شده می شود. بنابراین ، شکل دهی برای رابط های با سرعت کمتر توصیه می شود. از آنجا که شکل دهی به ترافیک (و Policing) می تواند سرعت بسته های خروجی از روتر را محدود کند ، یک سوال پیش می آید: “چگونه می توانیم ترافیک را از یک رابط با سرعت کمتر از میزان سرعت فیزیکی رابط خارج کنیم؟” برای اینکه این امکان وجود داشته باشد ، ابزارهای شکل دهی و Policing به طور مداوم منتقل نمی شوند. به طور خاص ، آنها تعداد مشخصی بیت یا بایت را با سرعت خط ارسال می کنند ، و سپس ، تا زمانی که به یک بازه زمانی مشخص (مثلاً یک هشتم ثانیه) برسد ارسال را متوقف می کنند. پس از رسیدن به فاصله زمان ، رابط دوباره مقدار مشخصی از ترافیک را با نرخ خط ارسال می کند. و منتظر می ماند تا فاصله زمانی بعدی رخ دهد. این فرآیند به طور مداوم تکرار می شود و به یک رابط اجازه می دهد تا یک پهنای باند متوسط ارسال کند که ممکن است کمتر از سرعت فیزیکی رابط باشد. به این پهنای باند متوسط [۱](CIR) گفته می شود. به تعداد بیت ها (واحد اندازه گیری استفاده شده با ابزارهای شکل دهی) یا بایت ها (واحد اندازه گیری های استفاده شده با ابزارهای policing ) که طی یک بازه زمانی ارسال می شود ، [۲](Bc) گفته می شود. فاصله زمان بندی به صورت Tc نوشته می شود.
به عنوان مثال ، فرض کنید که سرعت خط فیزیکی شما ۱۲۸ کیلوبیت بر ثانیه است ، اما CIR فقط ۶۴ کیلوبیت بر ثانیه است. همچنین ، فرض کنید در هر ثانیه هشت بازه زمانی وجود دارد (یعنی Tc = 1/8 ثانیه = ۱۲۵ میلی ثانیه) و در طی هر یک از این بازه های زمانی ، ۸۰۰۰ بیت (پارامتر committed burst ) با سرعت خط ارسال می شود. بنابراین ، در طول یک ثانیه ، ۸۰۰۰ بیت هشت بار (با سرعت خط) ارسال شد که در مجموع ۶۴۰۰۰ بیت در ثانیه است که CIR است. شکل ۹-۱۲ این شکل گیری ترافیک را به ۶۴Kbps در یک خط با سرعت ۱۲۸Kbps نشان می دهد.
[۱] committed information rate
[۲] committed burst
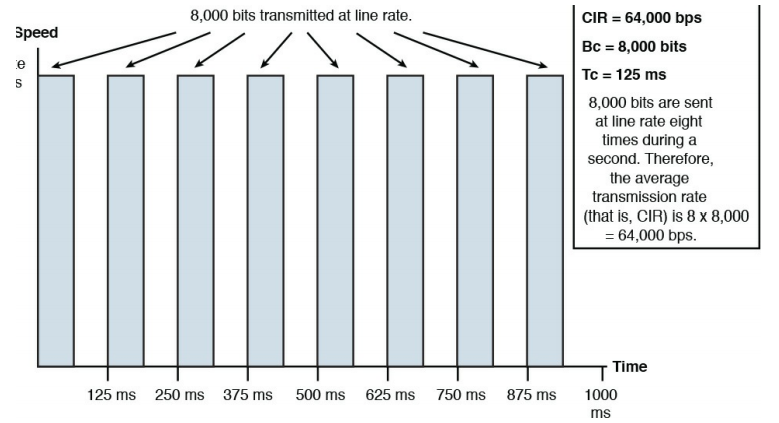
شکل ۱۲-۹ : Traffic Shaping
اگر تمام بیت های Bc (یا بایت) در طی یک زمان بندی ارسال نشده باشند ، یک گزینه برای بانکی کردن این بیت ها و استفاده از آنها در یک بازه زمانی آینده وجود دارد. پارامتری که اجازه می دهد این پهنای باند پتانسیل استفاده نشده را ذخیره کند ، پارامتر [۱](Be) اضافی نامیده می شود. پارامتر Be در یک پیکربندی شکل دهی ، حداکثر تعداد بیت ها یا بایت هایی را که می توانند بیش از Bc طی یک بازه زمانی ارسال شوند ، مشخص می کند ، اگر آن بیت ها واقعاً در دسترس باشند. برای در دسترس بودن آن بیت ها یا بایت ها ، باید در فواصل زمانی قبلی استفاده نشده باشند. با این حال ، ابزارهای policing از پارامتر Be برای تعیین حداکثر تعداد بایت قابل ارسال در یک بازه زمانی استفاده می کنند. بنابراین ، در پیکربندی policing ، اگر Bc برابر Be باشد ، هیچ انفجار اضافی رخ نمی دهد. در صورت وقوع انفجار بیش از حد ، ابزارهای policing این ترافیک اضافی را بیش از میزان ترافیک می دانند. ترافیکی که مطابق با CIR مشخص باشد (از آن فراتر نرود) توسط یک ابزار policing در نظر گرفته می شود که منطبق بر ترافیک است. رابطه بین Tc ، Bc و CIR با این فرمول آورده شده است: CIR = Bc / Tc. متناوباً ، فرمول را می توان به صورت Tc = Bc / CIR نوشت. بنابراین ، اگر می خواهید یک فاصله زمانی کوچکتر داشته باشید ، Bc کوچکتر را پیکربندی کنید.
Link Efficiency
برای استفاده بیشتر از پهنای باند محدود موجود در لینکهای با سرعت کم ، ممکن است تصمیم بگیرید که فشرده سازی یا تقسیم پیوند و اتصال به هم [۲](LFI) را پیاده سازی کنید. اگرچه می توانید میزان بار یا هدر بسته را برای حفظ پهنای باند فشرده کنید ، اما به عنوان یک مثال ، فشرده سازی هدر را در نظر بگیرید. با بسته های VoIP ، اندازه هدرهای لایه ۳ و لایه ۴ ۴۰ بایت است. با این حال ، بسته به نحوه رمزگذاری صدا ، حجم بار صوتی ممکن است فقط ۲۰ بایت باشد. در نتیجه ، VoIP بیشتر از فشرده سازی هدر برد ، در مقایسه با فشرده سازی payload سود میبرد . VoIP بسته ها را با استفاده از پروتکل [۳](RTP) ، که یک پروتکل لایه ۴ است ، ارسال می کند. سپس RTP در داخل UDP (پروتکل لایه ۴) کپسوله می شود ، سپس در داخل IP (در لایه ۳) کپسوله می شود. فشرده سازی هدر RTP (cRTP) می تواند هدرهای لایه ۳ و لایه ۴ را گرفته و آنها را فقط به اندازه ۲ یا ۴ بایت فشرده کند (در صورت استفاده نکردن از UDP checksums ۲ بایت و در صورت استفاده از UDP checksums 4 بایت) ، همانطور که در شکل ۱۳-۹ نشان داده شده است .
[۱] excess burst
[۲] link fragmentation and interleaving
[۳] Real-time Transport Protocol
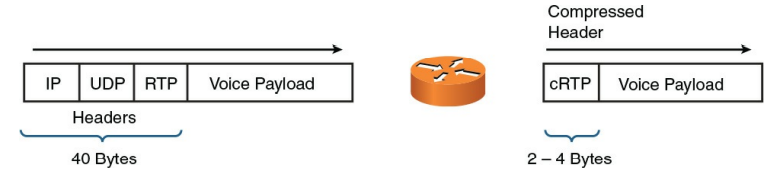
شکل ۱۳-۹ : RTP Header Compression (cRTP)
LFI به مسئله تاخیر سریال سازی یعنی همان زمان مورد نیاز برای خروج یک بسته از یک رابط ، می پردازد. به عنوان مثال ، یک بسته داده بزرگ ، روی پیوندی با سرعت کمتر ، ممکن است تأخیر بیش از حد برای بسته صوتی ایجاد کند ، زیرا این زمان برای خروج بسته داده از رابط مورد نیاز است. LFI بسته های بزرگ را تکه تکه می کند و بسته های کوچکتر را در میان قطعات قرار می دهد ، تاخیر سریال سازی توسط بسته های کوچکترکاهش می یابد. شکل ۹-۱۴ عملکرد LFI را نشان می دهد ،که بسته هایی با برچسب D بسته های داده ای هستند و بسته هایی با عنوان V بسته های صوتی هستند.

شکل ۱۴-۹ : Link Fragmentation and Interleaving (LFI)
مطالعه : طراحی شبکه SOHO
بر اساس آنچه از فصل های قبلی و این فصل آموخته اید ، این بخش شما را به چالش می کشد تا یک طراحی شبکه برای پاسخگویی به مجموعه ای از معیارها ایجاد کنید. از آنجا که طراحی شبکه بخشی از علم و بخشی از هنر است ، چندین طرح می توانند نیازهای مشخص شده را برآورده کنند. با این حال ، به عنوان مرجع ، این بخش یک راه حل ارائه می دهد ، در مقابل شما می توانید راه حل خود را مقایسه کنید.
سناریوی مطالعه موردی
هنگام کار در طراحی خود ، موارد زیر را در نظر بگیرید:
- پاسخگویی به همه الزامات
- محدودیت های فاصله رسانه ای
- انتخاب دستگاه شبکه
- فاکتورهای محیطی
- سازگاری با تجهیزات موجود و آینده
موارد زیر سناریوی طراحی و معیارهای طراحی این مطالعه موردی است:
همانطور که در شکل ۹-۱۵ نشان داده شده است ، شرکت ABC دو ساختمان (ساختمان A و ساختمان B) را در یک پارک بزرگ اداری اجاره می کند. پارک اداری دارای یک سیستم مجاری است که به رسانه های فیزیکی اجازه می دهد بین ساختمان ها حرکت کنند. فاصله (از طریق سیستم مجرا) بین ساختمان A و ساختمان B یک کیلومتر است.
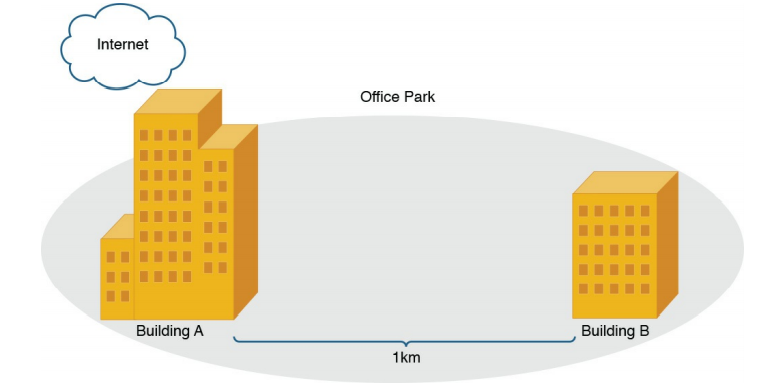
شکل ۱۵-۹ : Case Study Topology
- شرکت ABC از آدرس کلاسB ، ۱۶٫۰٫۰/۱۶ برای سایت های خود استفاده خواهد کرد. شما باید این شبکه کلاسه را نه تنها برای پشتیبانی از دو ساختمان (یک زیر شبکه در هر ساختمان) ، بلکه برای اجازه دادن به حداکثر پنج سایت در آینده ، با ادامه رشد شرکت ABC ، زیر شبکه کنید.
- شرکت ABC باید از سرعت حداقل ۳۰ مگابیت بر ثانیه به اینترنت متصل شود و این اتصال باید در ساختمان A برقرار شود.
- هزینه یک ملاحظه اولیه طراحی است ، در حالی که عملکرد یک ملاحظه دوم طراحی است.
- هر ساختمان شامل دستگاه های مختلف سرویس گیرنده Wi-Fi (به عنوان مثال تلفن های هوشمند ، تبلت ها و لپ تاپ ها) است.
جدول ۹-۳ تعداد میزبانهای موجود در هر ساختمان و تعداد طبقات موجود در هر ساختمان را مشخص می کند.
جدول ۳-۹ : Case Study Information for Buildings A and B

طرح شما باید شامل اطلاعات زیر باشد:
- آدرس شبکه و subnet mask برای ساخت A
- آدرس شبکه و subnet mask برای ساختمان B
- انتخاب media لایه ۱
- انتخاب دستگاه لایه ۲
- انتخاب دستگاه لایه ۳
- طراحی بی سیم
- هر عنصر طراحی بر اساس ملاحظات زیست محیطی است
- توضیحی در مورد محل صرفه جویی در هزینه در نتیجه معاملات عملکردی
- یک نمودار توپولوژیکی از طرح پیشنهادی
در صفحه های جداگانه کاغذ ، طرح شبکه خود را بکشید. پس از اتمام طراحی خود ، با تضاد معیارهای ذکر شده در برابر طرح خود ، یک بررسی عقلانی انجام دهید. سرانجام ، اگر بخاطر داشته باشید که چندین طرح می توانند معیارهای طراحی را برآورده کنند ، می توانید راه حل پیشنهادی زیر را مرور کنید. در دنیای واقعی ، مرور منطق موجود در سایر طرح ها اغلب می تواند دیدگاه تازه ای برای طراحی های آینده به شما بدهد.
راه حل پیشنهادی
این راه حل پیشنهادی با تخصیص آدرس IP آغاز می شود. سپس ، به media لایه ۱ توجه می شود و سپس دستگاه های لایه ۲ و لایه ۳ مورد توجه قرار می گیرند. تصمیمات طراحی بی سیم ارائه می شود. عناصر طراحی بر اساس عوامل محیطی مورد بحث قرار گرفته است. راه حل پیشنهادی همچنین به چگونگی صرفه جویی در هزینه از طریق مبادلات عملکرد اشاره می کند. در پایان ، یک نمودار توپولوژیکی از راه حل پیشنهادی ارائه شده است.
آدرس دهی IP
سوالاتی که ممکن است هنگام طراحی آدرس IP یک شبکه بپرسید شامل موارد زیر است:
- چه تعداد هاست (اکنون و در آینده) برای پشتیبانی نیاز دارید؟
- (اکنون و در آینده) برای پشتیبانی به چند زیر شبکه نیاز دارید؟
با توجه به سناریو ، می دانید که هر زیرشبکه باید حداقل ۲۰۰ میزبان را در خود جای دهد. همچنین ، می دانید که باید حداقل پنج زیر شبکه را در خود جای دهید. در این راه حل ، subnet mask بر اساس تعداد زیرشبکه مورد نیاز است. هشت زیر شبکه با ۳ بیت قرض پشتیبانی می شوند ، در حالی که دو قرض گرفته شده فقط چهار زیر شبکه را پشتیبانی می کنند ، بر اساس این فرمول:
تعداد زیر شبکه = ۲s
که sدر آن تعداد بیت های قرض گرفته شده است
با ۳ بیت وام گرفته شده ، ۱۳ بیت برای آدرس دهی IP میزبان باقی مانده است که برای قرار دادن ۲۰۰ آدرس IP میزبان بسیار بیشتر از نیاز است. این ۳ بیت وام گرفته شده subnet mask 255.255.224.0 را ارائه می دهد. از آنجا که سومین octet آخرین octet است که دارای یک باینری ۱ در subnet mask است ،این interesting octet است. اندازه بلوک را می توان با کسر مقدار اعشاری زیرشبکه interesting octet از ۲۵۶ محاسبه کرد (یعنی ۳۲=۲۲۴-۲۵۶). از آنجا که اندازه بلوک ۳۲ و interesting octet سومین octet است ،این زیرشبکه با subnet mask 255.255.224.0 (یعنی / ۱۹) ایجاد می شوند:

همانطور که در جدول ۹-۴ نشان داده شده است ، دو زیرشبکه اول برای زیر مجموعه ساختمان A و ساختمان B انتخاب شده اند.
جدول ۴-۹ : Case Study Suggested Solution: Network Addresses

Media لایه ۱
سوالاتی که ممکن است هنگام انتخاب انواع رسانه لایه ۱ شبکه بپرسید ، شامل موارد زیر است:
- از چه سرعتی (اکنون و در آینده) باید پشتیبانی کرد؟
- چه فواصل بین دستگاه ها باید پشتیبانی شود (اکنون و در آینده)؟
در هر ساختمان ، کابل کشی بدون محافظ (UTP) (Cat 6a) برای اتصال اجزای شبکه انتخاب می شود. نصب بر اساس Gigabit Ethernet است. با این حال ، اگر دستگاه های ۱۰ گیگابیتی اترنت در آینده نصب شوند ، Cat 6a برای مسافت های طولانی ۱۰۰ متر برای ۱۰GBASE-T درجه بندی می شود. فاصله ۱ کیلومتری بین ساختمان A و ساختمان B برای کابل کشی UTP بسیار زیاد است. بنابراین ، فیبر چند حالته (MMF) انتخاب می شود. سرعت پیوند فیبر ۱Gbps خواهد بود. جدول ۹-۵ خلاصه را نشان میدهد
جدول ۵-۹ : Case Study Suggested Solution: Layer 1 Media

دستگاه های لایه ۲
سوالاتی که ممکن است هنگام انتخاب دستگاه های لایه ۲ در شبکه پرسیده شود شامل موارد زیر است:
- سوئیچ ها کجا قرار می گیرند؟
- تراکم پورت مورد نیاز سوئیچ ها (اکنون و در آینده) چیست؟
- چه ویژگی های سوئیچ نیاز به پشتیبانی دارند (به عنوان مثال STP یا LACP)؟
- از چه نوع رسانه ای برای اتصال به سوئیچ ها استفاده می شود؟
مجموعه ای از سوئیچ های اترنت دستگاه های شبکه را در هر ساختمان به هم متصل می کند. فرض کنید ۲۰۰ میزبان در ساختمان A در سه طبقه نسبتاً مساوی توزیع شده اند (هر طبقه تقریباً ۶۷ میزبان دارد). بنابراین ، هر طبقه دارای یک کمد سیم کشی شامل دو کلید اترنت است: یک سوئیچ تراکم ۴۸ پورت و یک سوئیچ تراکم ۲۴ پورت. هر کلید با استفاده از چهار اتصال منطقی با هم و با استفاده از پروتکل کنترل تجمع پیوند (LACP) به یک سوئیچ چند لایه واقع در ساختمان A متصل می شود.
توجه
تجمیع لینک به عنوان port aggregation نیز شناخته می شود. CompTIA اصطلاح port aggregation رابیشتر ترجیح میدهد .
در داخل ساختمان B ، دو سوئیچ اترنت ، هر کدام با ۴۸ پورت ، و یک سوییچ اترنت ، با ۲۴ پورت ، در یک کمد سیم کشی نصب شده است. این سوئیچ ها با استفاده از چهار اتصال منطقی همراه با LACP در یک پیکربندی انباشته بهم متصل می شوند. یکی از سوئیچ ها دارای یک درگاه MMF است که به آن امکان می دهد از طریق فیبر به سوئیچ چند لایه ساخت A متصل شود.
جدول ۹-۶ خلاصه ای از گزینه های سوئیچ است.
جدول ۶-۹ : Case Study Suggested Solution: Layer 2 Devices

دستگاه لایه ۳
سوالاتی که ممکن است هنگام انتخاب دستگاه های لایه ۳ برای شبکه بپرسید شامل موارد زیر است:
- چه تعداد رابط مورد نیاز است (اکنون و در آینده)؟
- چه نوع رابط هایی باید پشتیبانی شوند (اکنون و در آینده)؟
- کدام پروتکل مسیریابی (یا پروتکل ها) باید پشتیبانی شود؟
- چه ویژگی های روتر (به عنوان مثال ، HSRP یا ویژگی های امنیتی) باید پشتیبانی شوند؟
دستگاه های لایه ۳ از یک سوئیچ چند لایه در ساختمان A تشکیل شده اند. همه سوئیچ های موجود در ساختمان A با استفاده از چهار لینک بسته LACP به سوئیچ چند لایه برمی گردند. سوئیچ چند لایه حداقل به یک پورت MMF مجهز است که امکان اتصال با یکی از سوئیچ های اترنت در ساختمان B را فراهم می کند. سوئیچ چند لایه از طریق اتصال Fast Ethernet به یک روتر متصل می شود. این روتر شامل یک رابط سریال است که از طریق اتصال T3 به اینترنت متصل می شود.
طراحی بی سیم
سوالاتی که ممکن است هنگام طراحی بخش بی سیم یک شبکه بپرسید شامل موارد زیر است:
- چه سرعتهای بی سیم نیاز به پشتیبانی دارند (اکنون و در آینده)؟
- چه فاصله هایی بین دستگاه های بی سیم و نقاط دسترسی بی سیم باید پشتیبانی شود (اکنون و در آینده)؟
- چه استانداردهای بی سیم IEEE نیاز به پشتیبانی دارد؟
- از چه کانال هایی باید استفاده کرد؟
- نقاط دسترسی بی سیم کجا باید قرار بگیرند؟
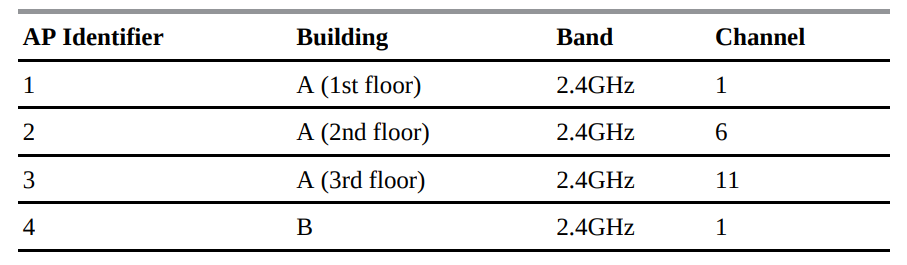
از آنجا که شبکه نیاز به پشتیبانی از سرویس گیرنده های مختلف Wi-Fi دارد ، باند ۲٫۴GHz انتخاب می شود. در داخل ساختمان A ، یک نقطه دسترسی بی سیم (AP) در هر طبقه از ساختمان قرار داده شده است. برای جلوگیری از تداخل ، کانالهای غیر همپوشانی ۱ ، ۶ و ۱۱ انتخاب می شوند. باند ۲٫۴ گیگاهرتز امکان سازگاری با IEEE 802.11b / g / n را نیز فراهم می کند. در داخل ساختمان B ، یک AP بی سیم تنها مشتریان Wi-Fi را در خود جای می دهد. جدول ۹-۷ خلاصه ای از انتخاب AP بی سیم است.
جدول ۷-۹ : Case Study Suggested Solution: Wireless AP Selection
فاکتورهای محیطی
سوالاتی که ممکن است هنگام در نظر گرفتن عوامل محیطی یک طراحی شبکه بپرسید ، شامل موارد زیر است:
- چه کنترل دما و رطوبت در اتاق های حاوی تجهیزات شبکه وجود دارد؟
- برای تأمین برق تجهیزات شبکه در صورت قطع برق ، به چه سیستم های افزونگی برق نیاز است؟
از آنجا که کلید چند لایه در ساختمان A می تواند یک نقطه خرابی برای کل شبکه باشد ، سوئیچ چند لایه در یک اتاق با تهویه مناسب قرار داده می شود ، که در صورت خرابی تهویه هوا می تواند باعث اتلاف گرما شود. برای افزایش بیشتر در دسترس بودن سوئیچ چند لایه ، سوئیچ به یو پی اس متصل است که می تواند به سوئیچ چند لایه کمک کند تا در صورت قطع شدن برق برای مدت کوتاهی کار کند. محافظت در برابر قطعی طولانی مدت برق می تواند با افزودن یک ژنراتور حاصل شود. با این حال ، هیچ ژنراتوری به دلایل بودجه ای در این طرح گنجانده نشده است.
پس انداز هزینه در مقابل عملکرد
هنگام جذب کلیه عناصر طراحی ، باید محدودیت های بودجه را در برابر معیارهای عملکرد شبکه بسنجید. در این مثال ، اترنت گیگابیتی به جای اترنت ۱۰ گیگابایتی انتخاب شده است. علاوه بر این ، ارتباط بین ساختمان A و ساختمان B می تواند به یک bottleneck تبدیل شود زیرا با سرعت ۱ گیگابیت بر ثانیه کار می کند ، گرچه تجمع چندین لینک ۱ گیگابیت بر ثانیه را انتقال می دهد. با این حال ، صرفه جویی در هزینه با استفاده از رابط های سوئیچ ۱ گیگابیت بر ثانیه در مقابل رابط های ۱۰ گیگابیت بر ثانیه یا بسته ای از چندین لینک فیبر ۱ گیگابیت بر ثانیه حاصل می شود
توپولوژی
شکل ۹-۱۶ توپولوژی طرح پیشنهادی را بر اساس مجموعه تصمیمات طراحی قبلاً ذکر شده نشان می دهد.
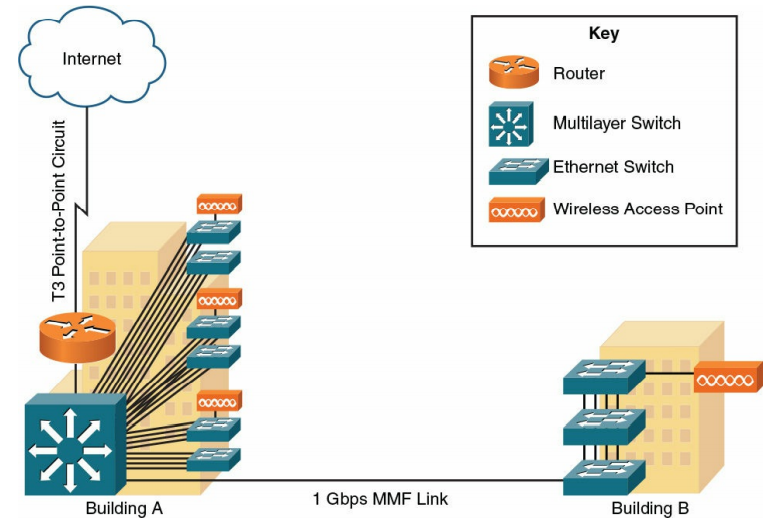
شکل ۱۶-۹ : توپولوژی Case Study Proposed
مطالعه موردی در دنیای واقعی
طراحی شبکه Acme، Inc شامل تحمل خطا در چندین نقطه از شبکه است. لینک هایی که از MDF طبقه پایین به کمدهای سیم کشی می روند به صورت جفت های زائد اجرا می شوند ، بنابراین در صورت خرابی یک جفت یا خرابی یک رابط ، جفت فیبر دیگر و رابط های مرتبط می توانند ترافیک را به جلو هدایت کنند. عملکرد مسیریابی در طبقه پایین واقع شده است و هر VLAN (و زیر شبکه مرتبط) دارای یک جفت روتر است که به عنوان یک گروه HSRP عمل می کنند. فایروال هایی که ترافیک موجود در لبه شبکه های شرکت را کنترل می کنند نیز در یک active-active failover pair تنظیم می شوند. VLAN اختصاصی فقط برای ترافیک صوتی در شبکه سیمی با علامت گذاری مناسب تنظیم شده است. روترها و سوئیچ ها برای شناسایی ترافیک صوتی براساس علائم آن پیکربندی شده اند و در صورت وجود ازدحام ، ترافیک صوتی برای حمل و نقل از طریق شبکه اولویت درمان را دارد. سرورهای Active Directory که شرکت داخلی از آنها استفاده می کند ، با استفاده از VMware’s vSphere بر روی یک پلت فرم سخت افزاری مجازی اجرا می شوند. ویژگی تحمل خطا (FT) که توسط VMware ارائه می شود ، در صورت خرابی سرورهای اصلی ، یک نسخه پشتیبان از سرورهای Active Directory در دسترس خواهد داشت. اگر مسیر Multiprotocol Label Switching (MPLS) از طریق WAN اصلی از طریق ارائه دهنده خدمات اصلی از کار بیفتد ، از طریق اینترنت (از طریق ارائه دهنده خدمات دوم) از VPN استفاده می شود. سطوح غیرطبیعی بالای بسته های [۱](ICMP) که از اینترنت به سمت سایت اصلی می روند ، در ارائه دهنده خدمات محدودیت نرخ دارد. با این کار احتمال حمله مبتنی بر ICMP که سعی دارد تمام پهنای باند موجود در سایت HQ را مصرف کند ، کاهش می یابد.
[۱] Internet Control Message Protocol
خلاصه
موضوعات اصلی ذکر شده در این فصل :
- در دسترس بودن شبکه ، از جمله نحوه اندازه گیری دسترس پذیری و دستیابی به آن از طریق طراحی اضافی ، مورد بحث قرار گرفت.
- استراتژی های بهینه سازی عملکرد ، از جمله استفاده از content caching ، تجمیع پیوندها و load balancing مورد بحث قرار گرفت.
- با تأکید بر شکل گیری ترافیک ، فناوری های مختلف QoS مورد بازبینی قرار گرفتند ، که می تواند سرعت انتقال داده ها را بر روی لینک WAN به CIR محدود کند.
به شما یک مطالعه موردی داده شد ، در آنجا شما را به چالش کشیدند که یک شبکه را برای رسیدن به مجموعه ای از معیارها طراحی کنید


